LevelDB介紹
*若圖片不清楚請左鍵點開放大高清

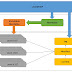
LevelDB是由Google開發的key-value NoSQL 資料庫,是基於LSM(Log-Structured-Merge-Tree)的實現,他會順序地記錄各種寫入操作。LevelDB存儲分為兩個部分,一部分存在記憶體(Memtable),一部分存在硬碟當中(SStable)。在記憶體中方便進行快速查找,若查找失敗,才去硬碟查找。當一段時間或是記憶體達到一定大小,記憶體會進行compact成sst文件再硬碟。

log,操作日誌記錄文件 memtable,數據庫存儲的內存結構 Immutable memtable,待落盤的數據庫內存數據 sstable,落盤後的磁盤存儲結構 manifest,LevelDB 元信息清單,包括數據庫的配置信息和中間使用的文件列表 current,當前正在使用的文件清單
對外界面
DB() { };
virtual ~DB();
static Status Open(const Options& options,
const std::string& name,
DB** dbptr);
virtual Status Put(const WriteOptions& options,
const Slice& key,
const Slice& value) = 0;
virtual Status Delete(const WriteOptions& options, const Slice& key) = 0;
virtual Status Write(const WriteOptions& options, WriteBatch* updates) = 0;
virtual Status Get(const ReadOptions& options,
const Slice& key, std::string* value ) = 0;
virtual Iterator* NewIterator(const ReadOptions& options) = 0;
virtual const Snapshot* GetSnapshot() = 0;
virtual void ReleaseSnapshot(const Snapshot* snapshot) = 0;
- 資料庫創建與刪除
DB(){};
virtual ~DB();
static Status Open(const Options& options,
const std::string& name,
DB** dbptr);
virtual Status Put(const WriteOptions& options,
const Slice& key,
const Slice& value) = 0; //寫入
virtual Status Delete(const WriteOptions& options, const Slice& key) = 0; //刪除
virtual Status Get(const ReadOptions& options,
const Slice& key, std::string * value) = 0; //讀取
virtual Status Write(const WriteOptions&
options, WriteBatch* updates) = 0;
virtual Iterator* NewIterator(const ReadOptions& options) = 0;
virtual const Snapshot* GetSnapshot() = 0; //創建
virtual void ReleaseSnapshot(const Snapshot* snapshot) = 0; //釋放
log結構分析
LevelDb使用的log採取文件紀錄的方式,且文件使用mmap方式操作,以提高效率。log存儲切分為32KB,每個32KB的數據塊存儲著log,每個log格式如下:

FIRST:代表Data是log剛開始的數據
MIDDLE:代表Data是log中間的數據
LAST:代表Data是log結束的數據
Data:log的實際數據
memtable 是LevelDB資料庫的記憶體存儲結構,採用了skip list的資料結構如下GIF圖:

其中:
另外Data Block 及 Meta Block 的存儲的格式都是統一的,請參考下圖

memtable結構分析
memtable 是LevelDB資料庫的記憶體存儲結構,採用了skip list的資料結構如下GIF圖:

其中每項的結構如下:
key_size | key_value | sequence_num&type | value_size | value
sequence_num: 為每次操作的順序號碼,用來表示數據的新舊程度。
type:
- ktypeValue:表示數據有效
- kTypeDeletion:表示數據無效,在進行delete操作時會打上這個標記
sstable結構分析
sstable每個最大2MB,屬於分層結構設計:

- level 0:最多存儲4個sstable
- level 1:存儲不超過10MB大小的sstable
- level 2:存儲不超過100MB大小的sstable
level 3 及之後:儲存大小不超過上一級的10倍
之所以這樣分層是為了提高查找效率,也是LevelDB名稱的由來。當每一層超過限制,會進行compaction操作,合併到上一層,回歸進行。
sstable 文件結構如下圖所示:

其中:
- Data Block: 以Key-Value的方式存儲實際數據。
- Meta Block:儲存索引訊息,用於快速查詢key是否存在Data Block中。
- Meta Index Block: 與Index Block類似,由一組Handle組成,不同的是這裡的Handle指向的Meta Block。
- Index Block: 記錄Data Block位置信息的Block,其中的每一條Entry指向一個Data Block,其Key值為所指向的Data Block最後一條數據的Key,Value為指向該Data Block位置的Handle。
- Footer:為於Table尾部,記錄指向Metaindex Block的Handle和指向Index Block的Handle。需要說明的是Table中所有的Handle是通過偏移量Offset以及Size一同來表示的,用來指明所指向的Block位置。Footer是SST文件解析開始的地方,通過Footer中記錄的這兩個關鍵元信息Block的位置,可以方便的開啟之後的解析工作。另外Footer種還記錄了用於驗證文件是否為合法SST文件的常數值Magicnum。
另外Data Block 及 Meta Block 的存儲的格式都是統一的,請參考下圖
其中
- Type:記錄當前Block的數據壓縮策略。
- crc:儲存Block中數據的校驗訊息。
Block中每條Entry是以Key-Value方式儲存的,並且Key按有序儲存,LevelDB巧妙利用這點,相鄰的key的Prefix能相同的特點減少儲存的數據量,例如Apple與ApplePen,第二個entry就只要儲存Pen的訊息即可。
架構以下分別說明:
- Shared Bytes:儲存相同部分之長度
- Unshared Bytes:儲存不同部分之長度
- Value Lentgh: 儲存Value的長度
- Key Delta:儲存不同部分之內容
- Value:儲存Value內容
這種方式非常好的減少數據儲存,但也產生一個風險,如果第一個entry數據損壞,其後與之相同的將無法恢復。為了減低這個風險,LevelDB引入重啟點,每隔固定的調數Entry會強制完整記錄自己的key,並將sharedBytes設為0。同時Block會將這些蟲起點的偏移量以及個數紀錄在Entry的Tailer中。
對於Meta Block來說,他保存了用於快速定位key是否在Data Block中的訊息,具體方式是
- 採用bloom filter的過濾機制,bloom filter 是一種hash機制,他對每一個key,會計算k個hash值,然後再k個bit位紀錄為1。當查找時,相應計算出k個hash值,然後對比k個bit是否為1,只要有一個不為1則不存在。
- 對於每個Data Block,所有的key值會傳入進行bloom filter 的hash計算,每個key存儲k個bit位置
*將來會寫一篇有關bloomfilter專門的文章
版本控制
對於log文件,每一個log文件會有一個唯一的sequence num,每創建一個新的log文件,sequence num會+1,當sequence num數越大,則表示文件越新。
對於每個key-value對,都會有一個相應的sequence,這樣若將來更新同一個key時,其sequence num也不同,如此一來便可以知道其誰新誰舊。
總結
這篇文章程式碼較少,比較多LevelDB宏觀介紹,接下來幾篇文章希望可以往原始碼裡面走。
參考資料
http://catkang.github.io/2017/01/17/leveldb-data.html
http://taobaofed.org/blog/2017/07/05/leveldb-analysis/

沒有留言:
張貼留言